Introduction
Resume screening is one of the most time-consuming aspects of the hiring process. HR teams often spend hours reviewing resumes to extract key information, evaluate candidates, and prepare summaries for hiring managers. In this tutorial, we’ll build an automated resume analyzer that handles this work for you, combining the power of Pipedream workflow automation, Claude AI for intelligent analysis, and DocuGenerate for professional PDF generation.
The workflow operates automatically whenever a new resume is added to a Dropbox folder. It extracts the text from the resume, uses Claude to analyze the candidate’s experience and qualifications, generates a structured summary with key insights, and creates a professional PDF report that your hiring team can review immediately. The entire process takes just seconds and requires no manual intervention.
This approach is particularly valuable for organizations that need to process multiple resumes quickly while maintaining consistency in candidate evaluation. By standardizing the analysis format and leveraging AI to extract insights, you can focus your time on interviewing the most promising candidates rather than spending hours on initial screening.
Understanding the Workflow
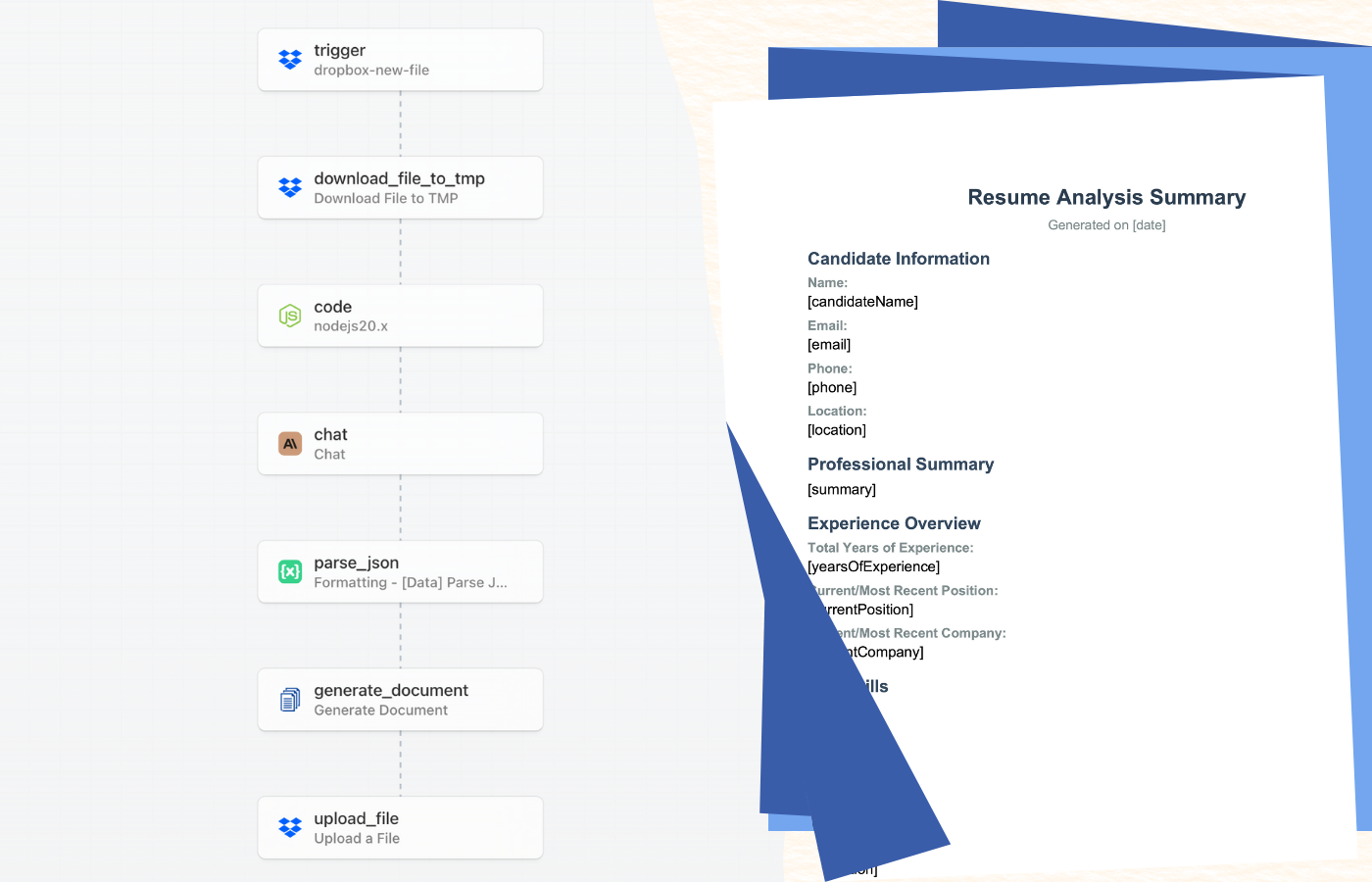
The complete workflow consists of seven connected steps that work together to transform a raw resume into a structured analysis report. Here’s how the process flows from start to finish:
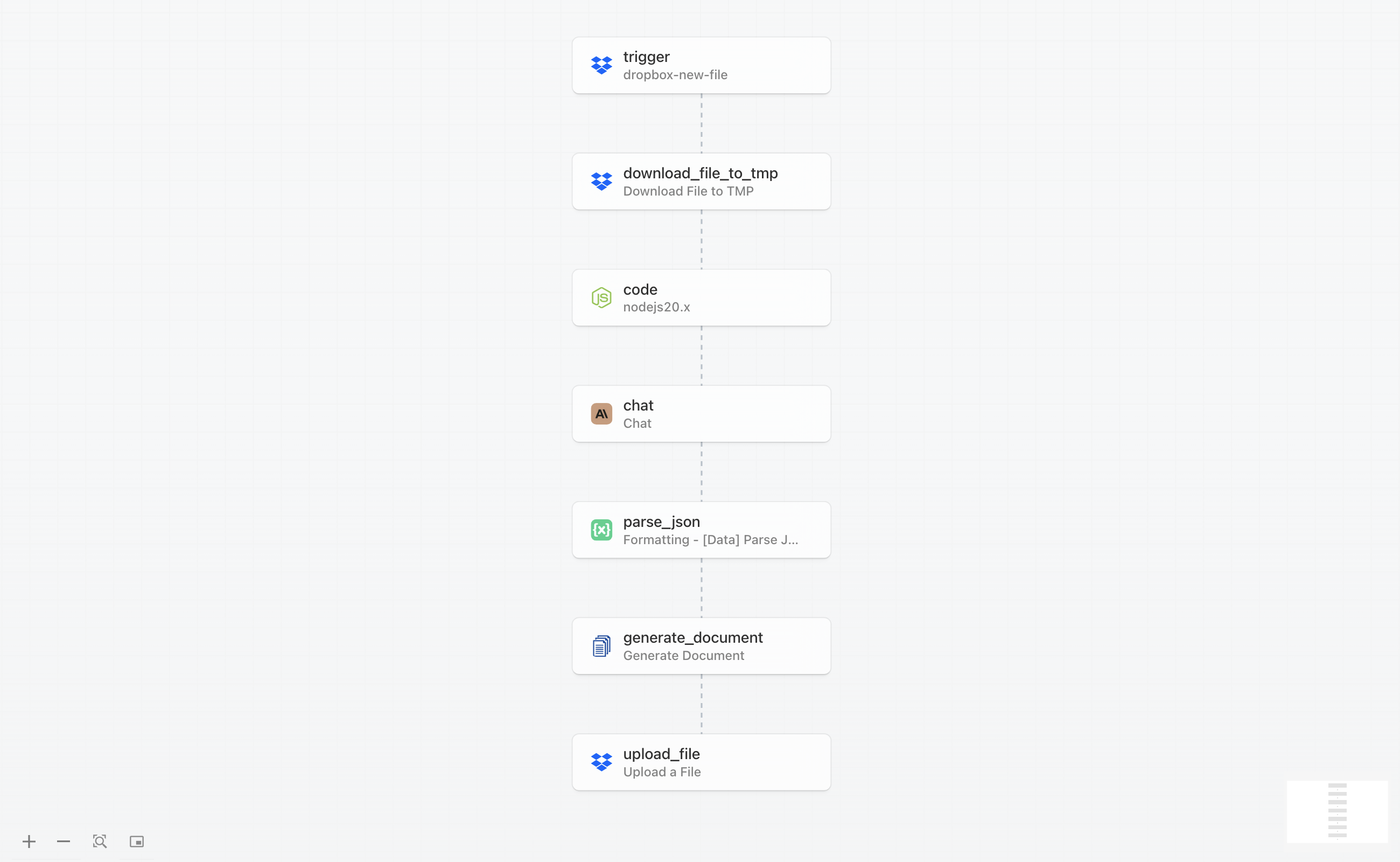
The workflow begins when you upload a resume to a monitored Dropbox folder. Pipedream detects the new file, downloads it, and extracts the text content from the PDF. This text is then sent to Claude AI with specific instructions to analyze the resume and extract key information like work experience, skills, education, and notable achievements. Claude returns a structured JSON response containing all the extracted data.
The JSON data is then passed to DocuGenerate along with a pre-designed template to generate a professional PDF summary. Once the document is created, it’s automatically uploaded back to Dropbox in a designated folder where your hiring team can access it. The entire process completes in under a minute, and you can process multiple resumes simultaneously simply by uploading them to the trigger folder.
Setting Up the Document Template
Before building the Pipedream workflow, we need to create a template that will format our resume analysis reports. The template uses DocuGenerate’s merge tags syntax to define where data from Claude’s analysis should appear in the final document. This ensures every candidate summary follows a consistent, professional format.
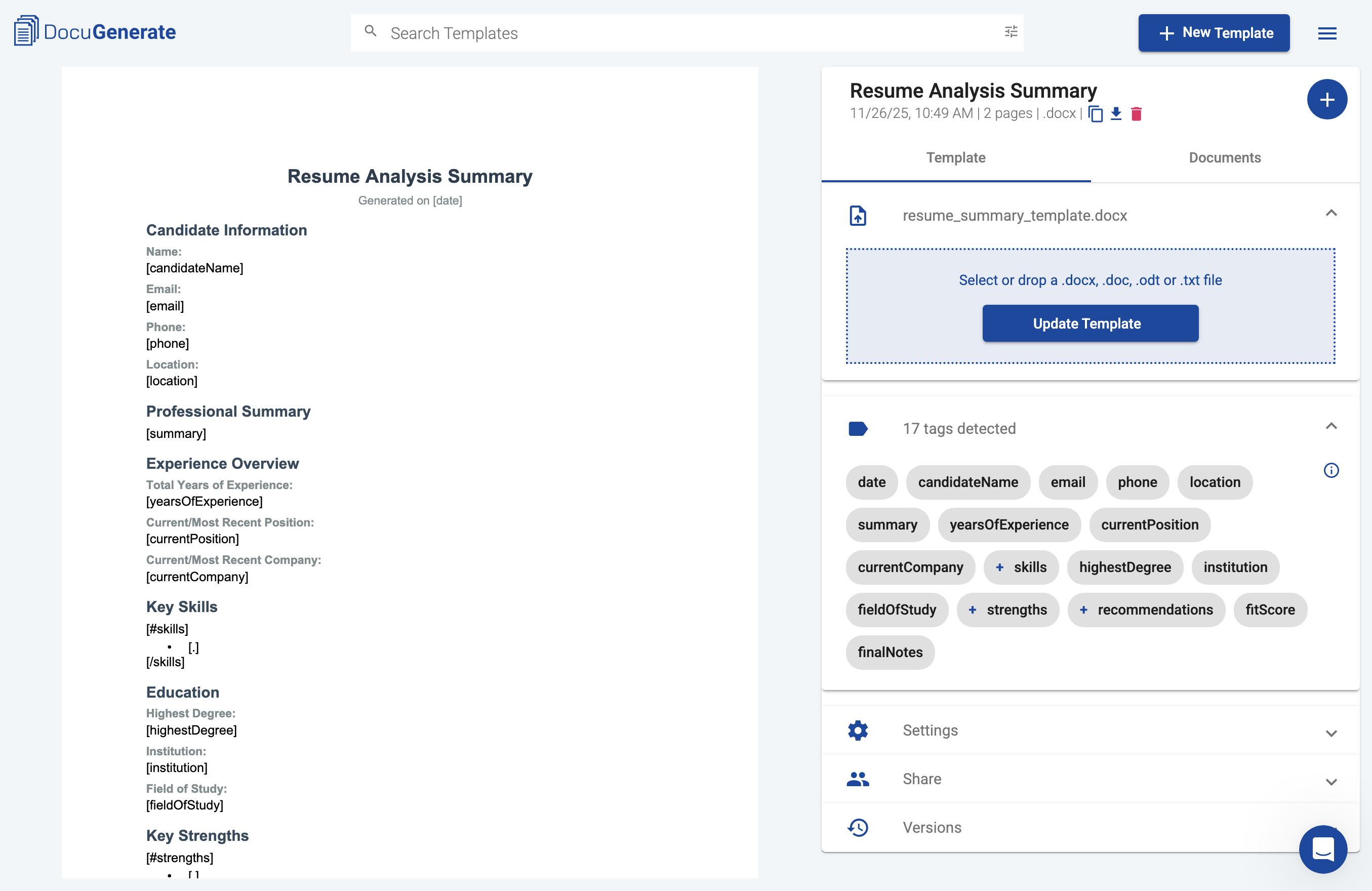
The template includes sections for candidate information (name, email, phone, location), a professional summary, experience overview, key skills, education, strengths, interview recommendations, and an overall assessment with a fit score. Some sections like skills, strengths, and recommendations use list syntax to display multiple items from arrays in the data. For example, the skills section uses [#skills] to begin the loop, [.] to display each skill as a bullet point, and [/skills] to end the loop.
You can download the complete template and upload it to your DocuGenerate account. Once uploaded, take note of the template name or ID, as you’ll need this information when configuring the document generation step in the workflow. With the template ready, we can now build the Pipedream workflow that will automate the entire analysis process.
Configuring the Dropbox Trigger
The workflow starts with a Dropbox trigger that monitors a specific folder for new files. This trigger is the entry point that activates the entire automation whenever a resume is uploaded. To configure this trigger, you’ll need to connect your Dropbox account to Pipedream and specify which folder to monitor.
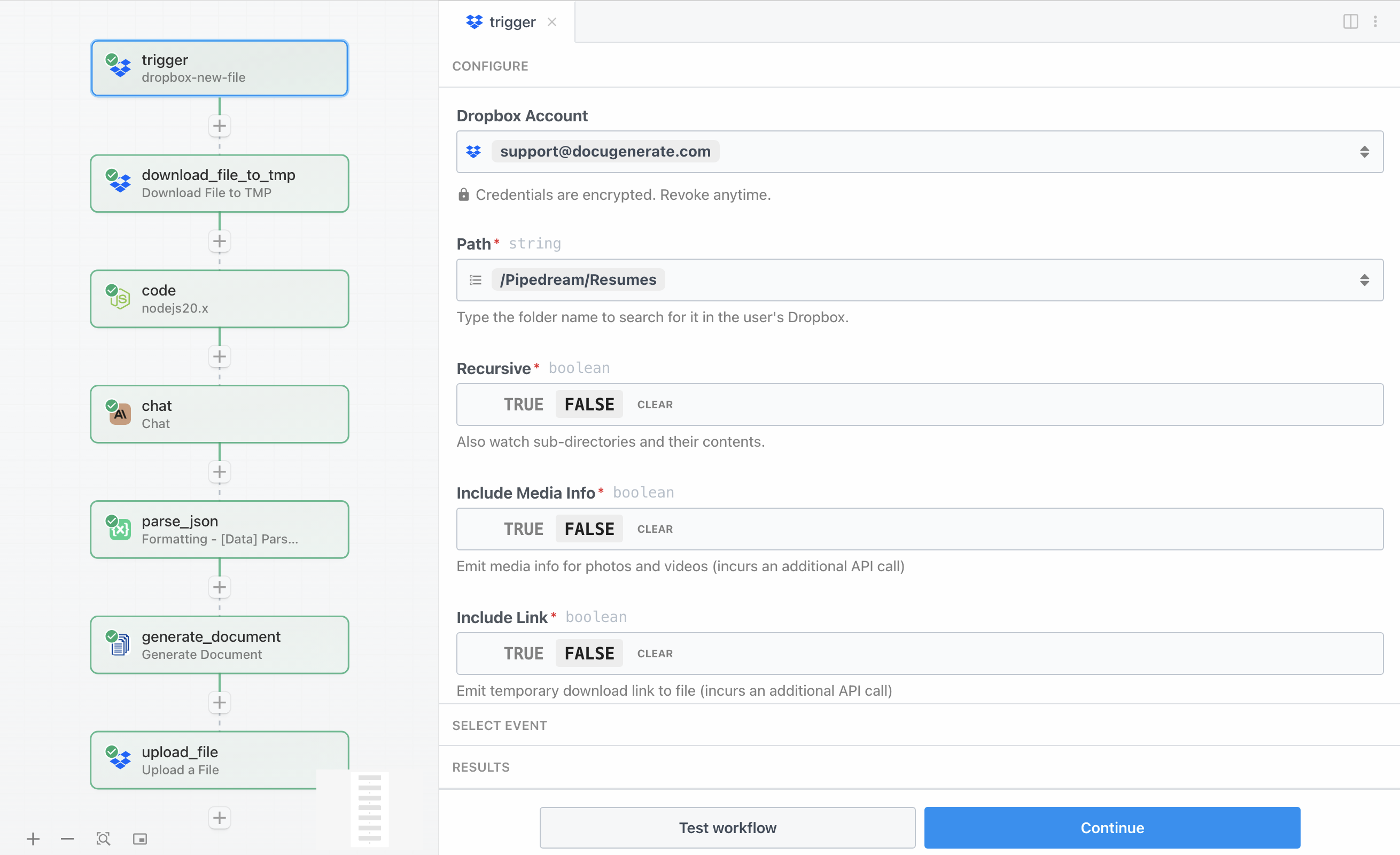
For this tutorial, we’re monitoring a folder called /Pipedream/Resumes. When you test the trigger with a sample resume, you’ll see that it returns metadata about the file including the filename, path, size, and modification dates. However, it’s important to note that the trigger only provides this metadata and not the actual file content. This is why we need a separate step to download the file, which we’ll configure in the next section.
The trigger activates immediately when a new file is detected, making the workflow responsive to your hiring needs. You can upload resumes throughout the day, and each one will be processed automatically without any manual intervention. This real-time processing ensures that candidate summaries are available to your team as quickly as possible.
Downloading the Resume File
After the trigger detects a new file, we need to actually download the file content before we can extract text from it. The Download File to TMP action retrieves the resume from Dropbox and saves it to Pipedream’s temporary storage, where subsequent steps can access it.
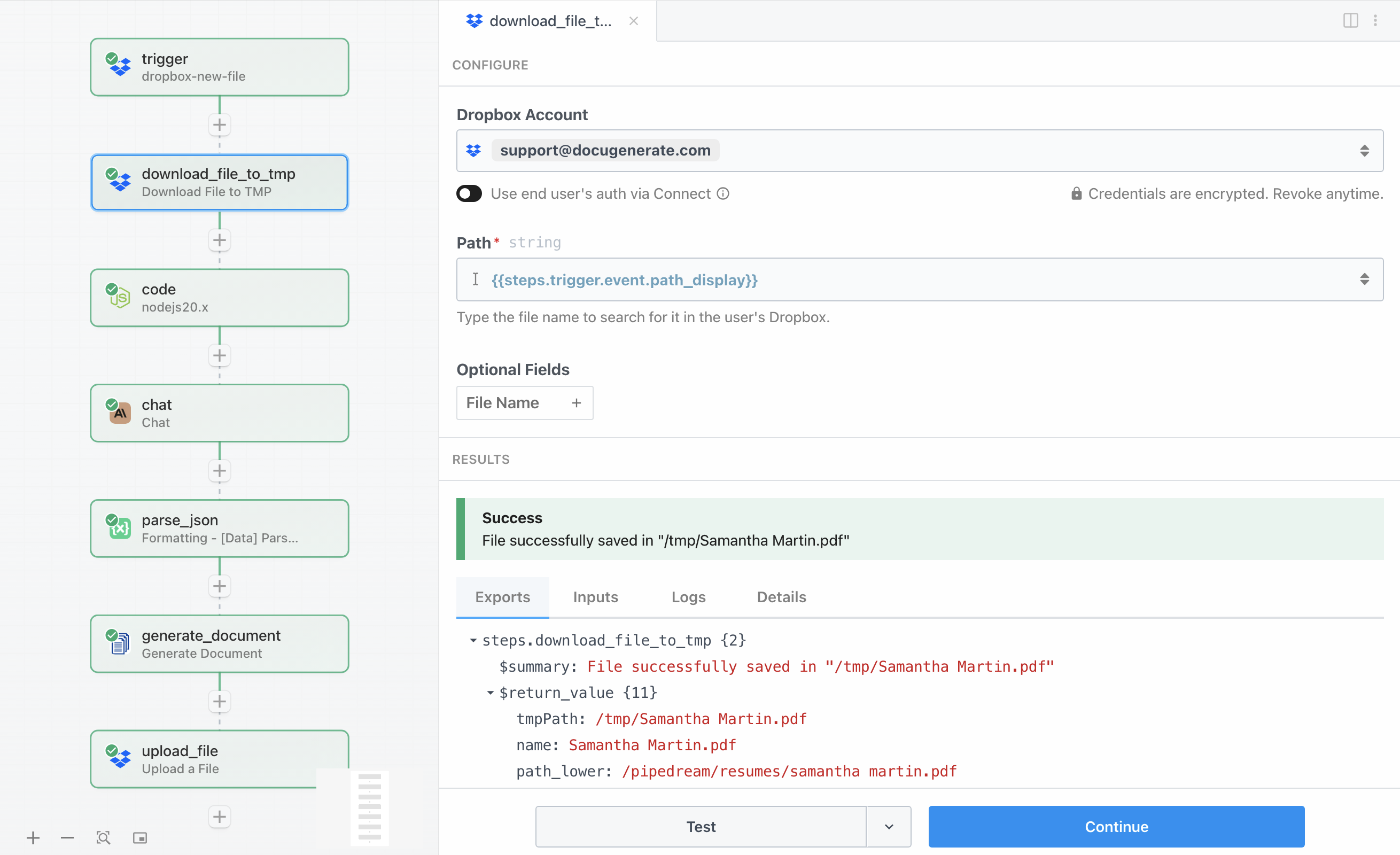
The configuration is straightforward. The Path parameter uses {{steps.trigger.event.path_display}} to reference the file path captured by the trigger. This action downloads the file and returns an object containing the temporary file path in the tmpPath property. The file remains in temporary storage throughout the workflow execution, which is perfect for processing and then discarding after the workflow completes.
The downloaded file is now ready for text extraction. The temporary file path will be used in the next step to read the PDF content and convert it into text that Claude can analyze.
With the resume downloaded to temporary storage, we now need to extract the text content from the PDF file. This step uses a Node.js code block with the pdf-parse library to read the PDF and convert it into plain text that Claude can analyze.
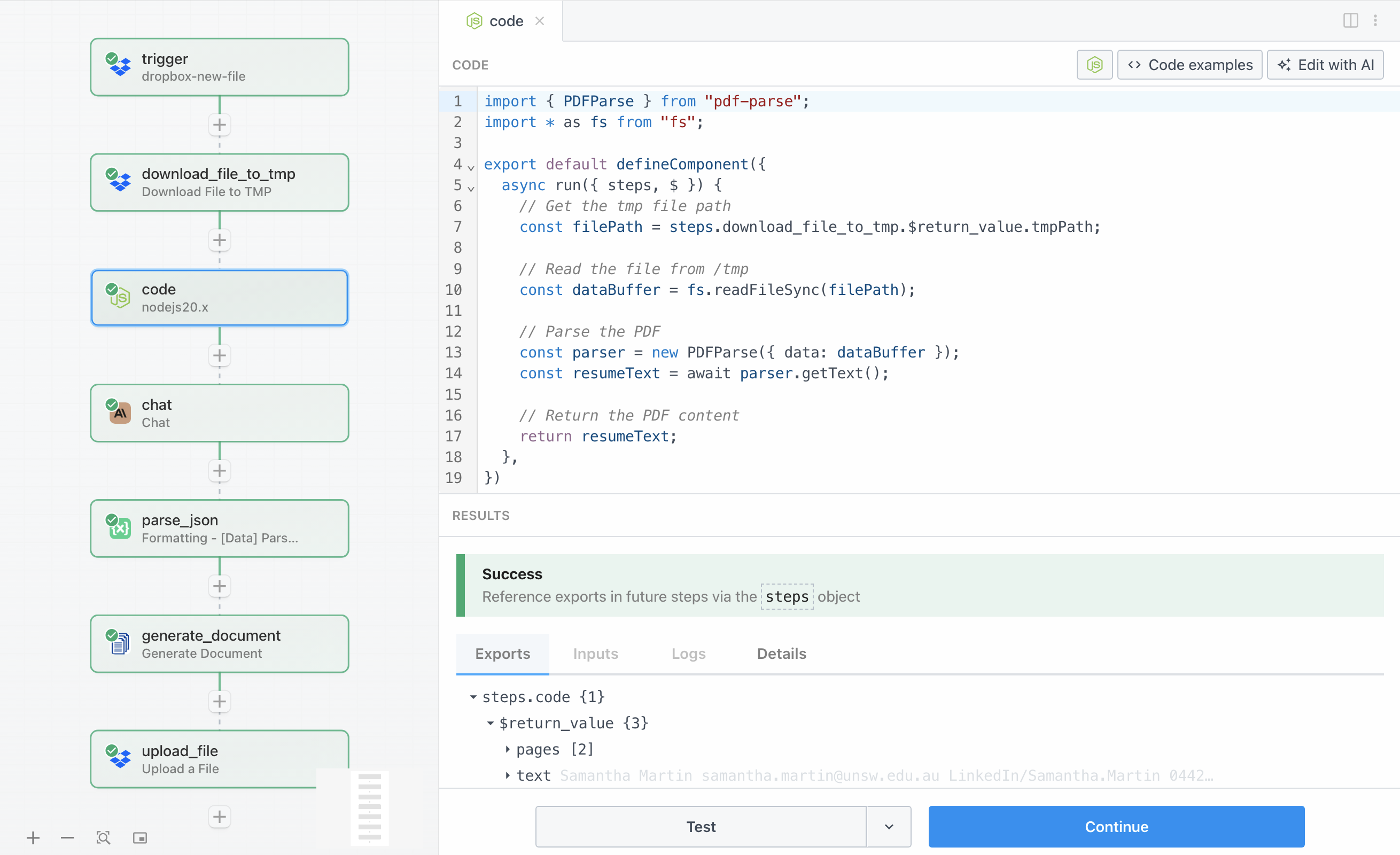
The code reads the file from the temporary path using Node.js’s built-in fs module, then passes the file buffer to pdf-parse for processing. The library handles the complexities of PDF parsing and returns the extracted text as a string.
import { PDFParse } from "pdf-parse";
import * as fs from "fs";
export default defineComponent({
async run({ steps, $ }) {
// Get the tmp file path
const filePath = steps.download_file_to_tmp.$return_value.tmpPath;
// Read the file from /tmp
const dataBuffer = fs.readFileSync(filePath);
// Parse the PDF
const parser = new PDFParse({ data: dataBuffer });
const resumeText = await parser.getText();
// Return the PDF content
return resumeText;
},
})
The extracted text is now available in resumeText and ready to be analyzed by Claude in the next step.
Analyzing the Resume with Claude
This is where the intelligence happens. The Claude API step sends the extracted resume text to Anthropic’s Claude AI with detailed instructions to analyze the content and return structured data in JSON format. Claude examines the resume and extracts key information including work experience, skills, education, and provides insights that would typically require manual review.
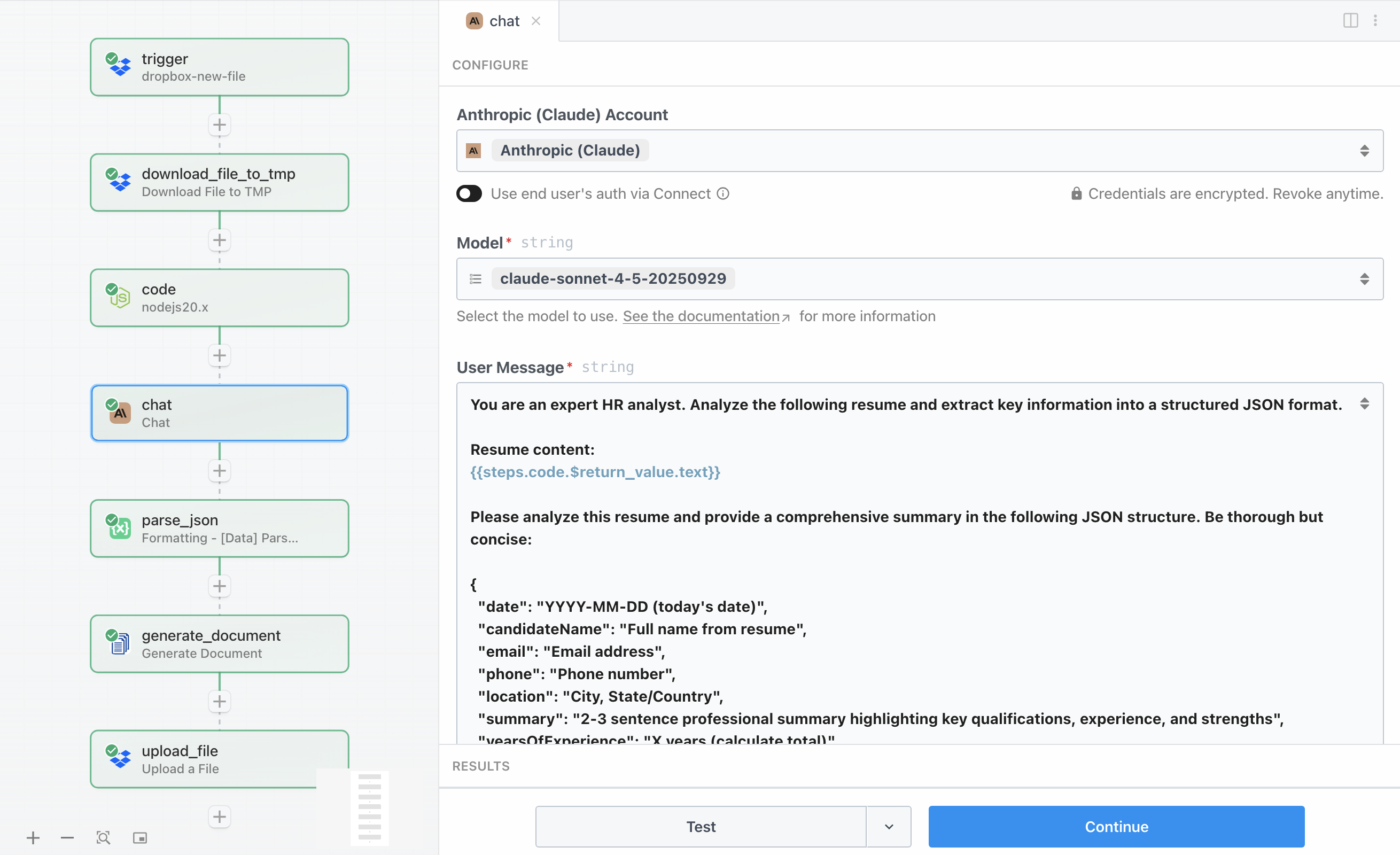
The configuration of the Chat with Anthropic (Claude) action requires your Anthropic API key, which you can obtain from your Anthropic account. The request uses the claude-sonnet-4-5-20250929 model, which provides an excellent balance of speed, cost, and analytical capability for this task. The Maximum Tokens to Sample parameter is set to 4096, which gives Claude enough space to return a comprehensive analysis with all the fields we need.
The prompt is carefully structured to guide Claude in extracting specific information and formatting it as valid JSON. Here’s the complete prompt that instructs Claude on what to analyze and how to structure the response:
You are an expert HR analyst. Analyze the following resume and extract key information into a structured JSON format.
Resume content:
{{steps.code.$return_value.text}}
Please analyze this resume and provide a comprehensive summary in the following JSON structure. Be thorough but concise:
{
"date": "YYYY-MM-DD (today's date)",
"candidateName": "Full name from resume",
"email": "Email address",
"phone": "Phone number",
"location": "City, State/Country",
"summary": "2-3 sentence professional summary highlighting key qualifications, experience, and strengths",
"yearsOfExperience": "X years (calculate total)",
"currentPosition": "Most recent job title",
"currentCompany": "Most recent company name",
"skills": [
"List 6-10 key technical and professional skills with proficiency levels where relevant"
],
"highestDegree": "Degree name (e.g., Bachelor of Science in Computer Science)",
"institution": "University/College name",
"fieldOfStudy": "Major/Field",
"strengths": [
"List 4-6 key strengths based on achievements, projects, and experience"
],
"recommendations": [
"List 4-5 specific interview questions or topics to explore based on their unique experience"
],
"fitScore": "Rate 1-10 based on overall qualifications and experience",
"finalNotes": "2-3 sentence overall assessment and hiring recommendation"
}
IMPORTANT INSTRUCTIONS:
- Extract all information directly from the resume
- If any field is not available in the resume, use "Not specified" or an empty array []
- For skills, include proficiency levels when they can be inferred from years of experience or explicit mentions
- Make the summary compelling but accurate
- Base the fitScore on years of experience, skill diversity, education, and career progression
- Ensure all JSON is properly formatted with no syntax errors
- Return ONLY the JSON object, no additional text or markdown formatting
CRITICAL OUTPUT REQUIREMENTS:
- Return ONLY the raw JSON object
- Do NOT wrap the JSON in markdown code blocks
- Do NOT include ```json or ``` markers
- Do NOT add any explanatory text before or after the JSON
- The response must start with { and end with }
- The entire response must be valid, parseable JSON
Claude processes the resume text and returns a JSON object containing all the extracted information. The response includes everything from basic contact details to insightful recommendations for interview questions based on the candidate’s unique experience. This structured format makes it easy to pass the data to DocuGenerate for document generation in the next step.
Parsing the JSON Response
Claude returns its analysis as a JSON string, but we need to convert this into a structured object that we can work with in subsequent steps. Pipedream’s built-in Parse JSON action found under Formatting → Data handles this conversion automatically.
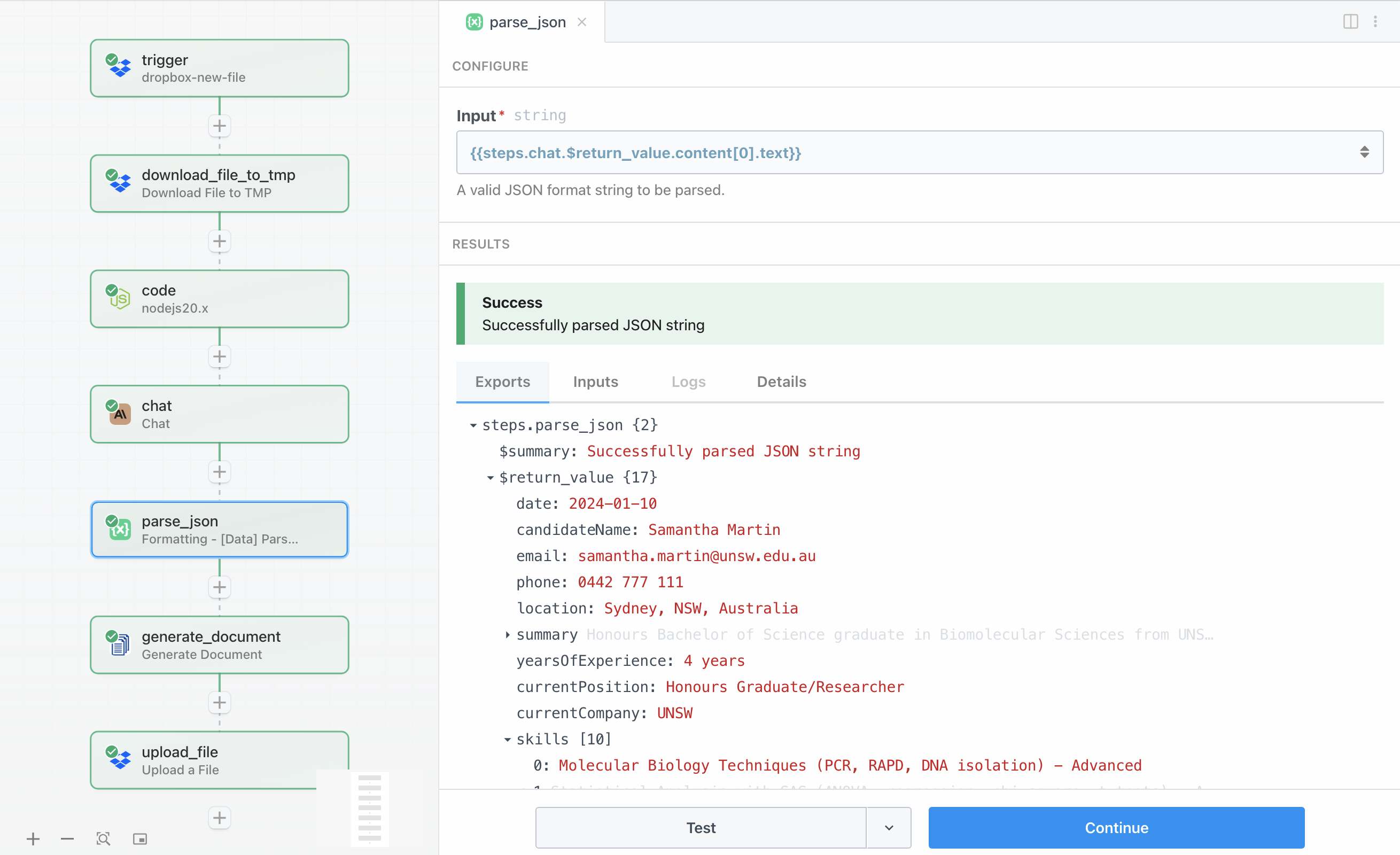
The configuration simply takes the Claude response from {{steps.chat.$return_value.content[0].text}} and parses it into a structured object. This parsed data becomes available to all subsequent steps in the workflow, allowing us to reference specific fields like {{steps.parse_json.$return_value.candidateName}} when we need them.
Having the data parsed into individual fields is particularly useful for dynamic file naming and for passing the complete dataset to DocuGenerate. The parsed object contains all the fields defined in our template: candidate information, summary, skills array, strengths array, recommendations array, and the overall assessment.
Generating the Summary Document
With the analyzed data now available as a structured object, we’re ready to generate the professional PDF summary. This step uses the DocuGenerate App on Pipedream to merge the data with our template and create a formatted document.
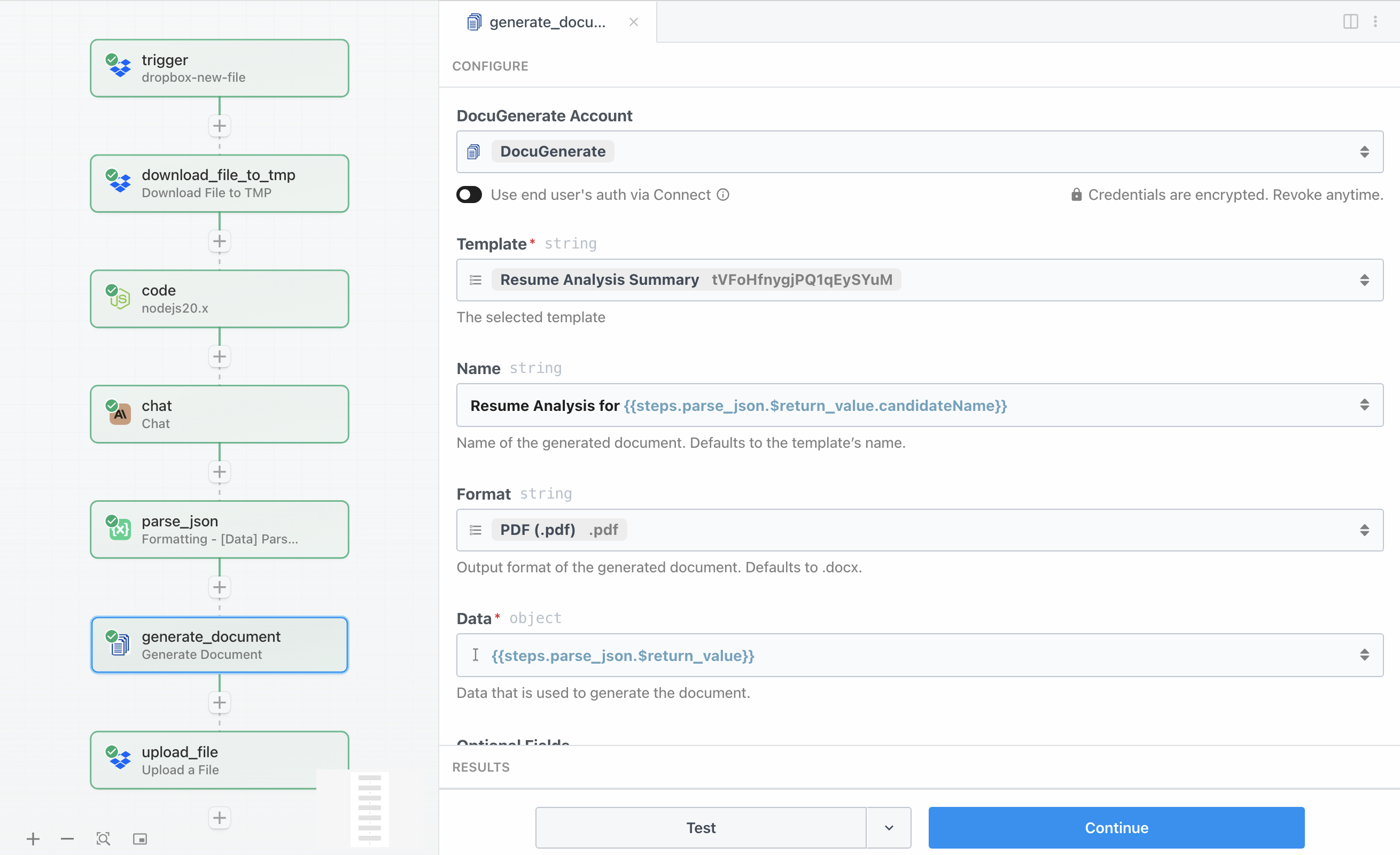
You’ll need your DocuGenerate API Key to set up a connection, which you can find in your account settings. The action configuration includes several important parameters:
- Template specifies the Resume Analysis Summary template from the setup section
- Name uses
Resume Analysis for {{steps.parse_json.$return_value.candidateName}} to create a dynamic filename based on the candidate’s name - Format is set to
PDF (.pdf) to generate a PDF document - Data contains the complete parsed JSON object
{{steps.parse_json.$return_value}} from Claude with all the candidate information
The API processes this request and returns a response containing a document_uri field, which is a URL pointing to the generated PDF document.
Uploading the Analysis to Dropbox
The final step completes the workflow by uploading the generated PDF analysis back to Dropbox where your hiring team can access it. The Upload a File action saves the document to a designated folder, organizing all candidate analyses in one location.
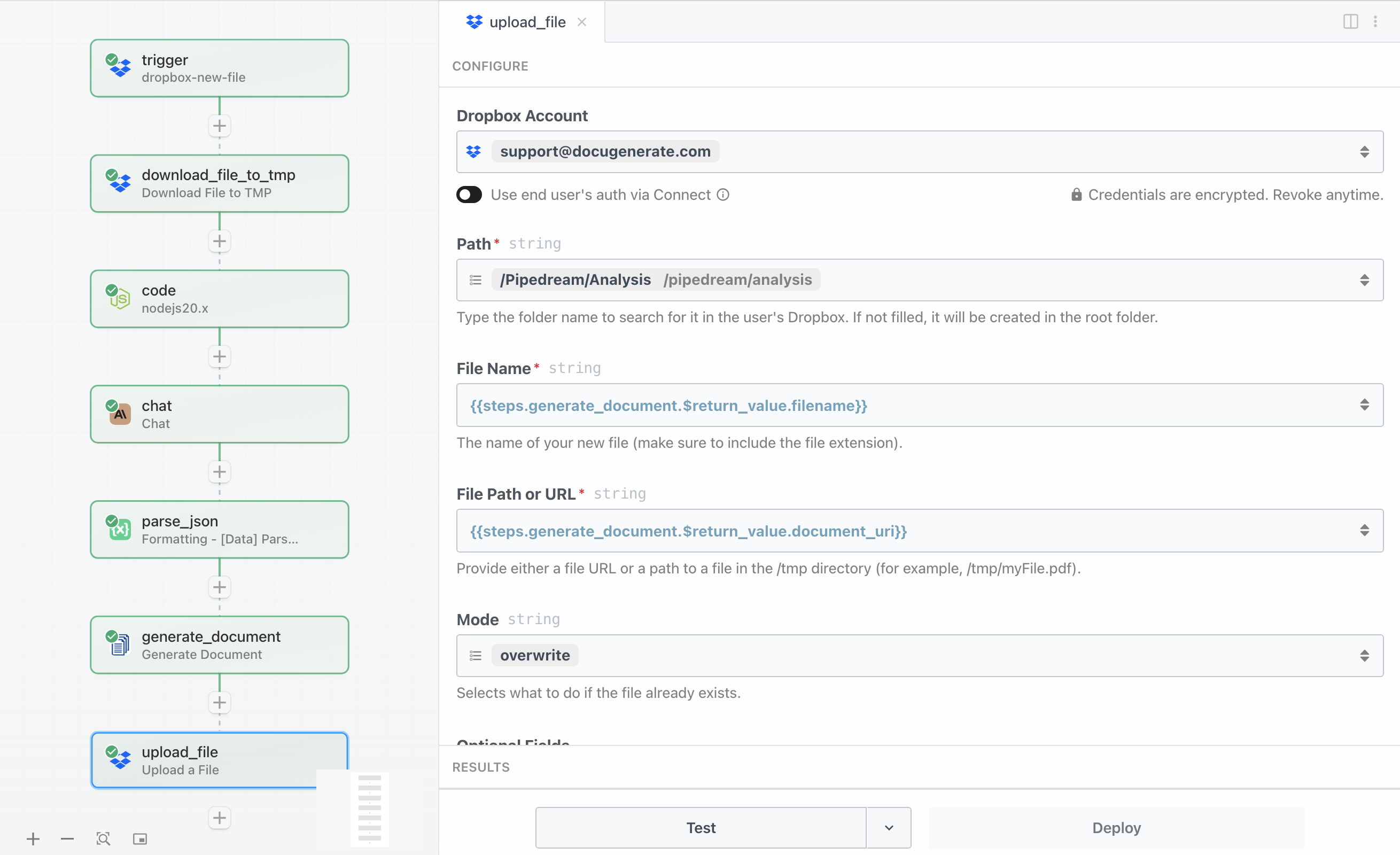
The configuration requires specifying the destination path and the file content to upload:
- Path specifies the
/Pipedream/Analysis destination folder - File Name is set to
{{steps.generate_document.$return_value.filename}} as the generated document’s file name - File Path or URL references the
{{steps.generate_document.$return_value.document_uri}} value from the previous step - Mode is set to
overwrite to define what to do if the file already exists
Once uploaded, the analysis is immediately available to your team, and you can optionally add an email notification step to alert hiring managers when a new candidate summary is ready for review.
Testing the Complete Workflow
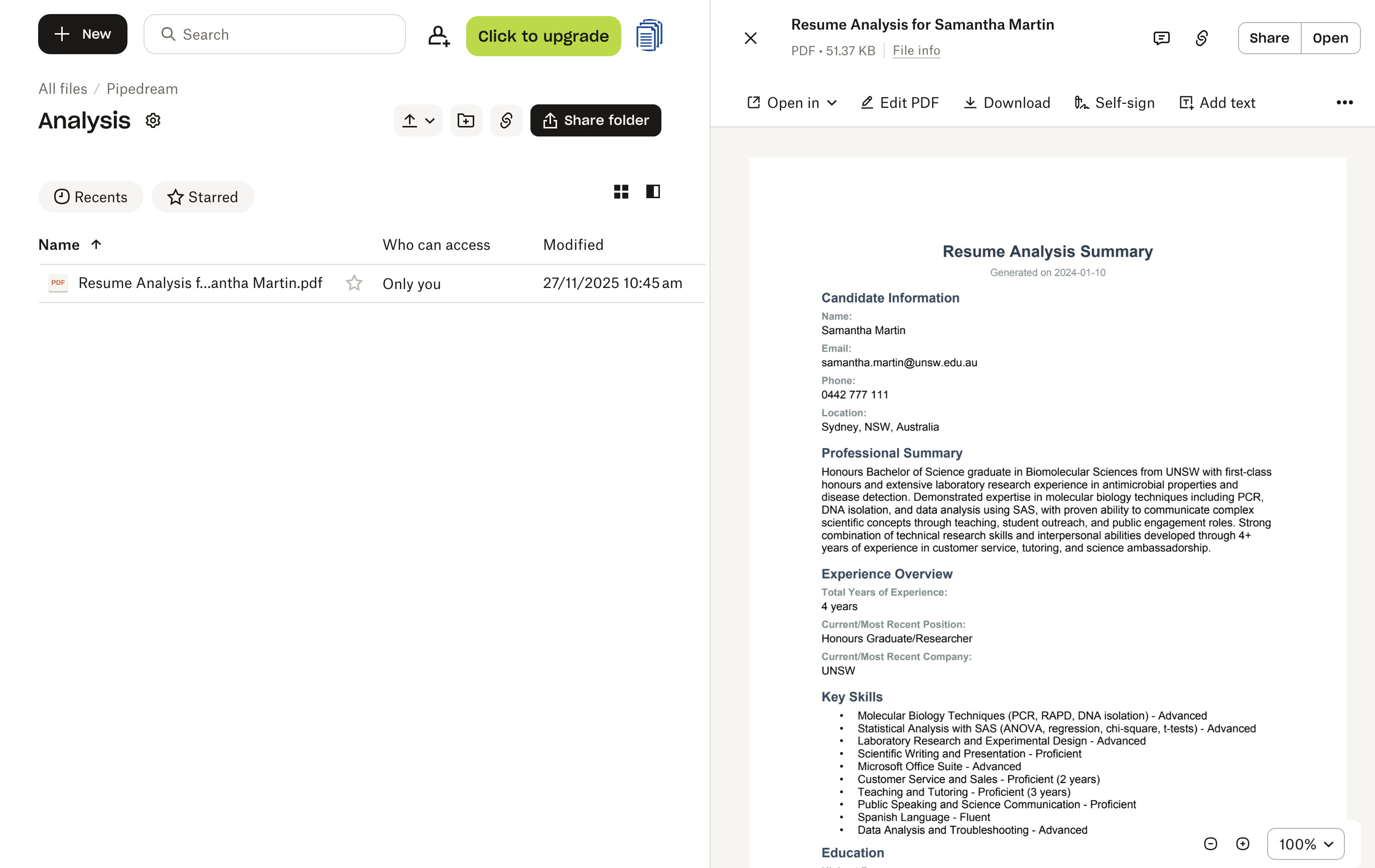
With all steps configured, the workflow is ready to process resumes automatically. To test it, simply upload a resume PDF to the /Pipedream/Resumes folder in your Dropbox. The workflow will detect the new file within seconds and begin processing it through each step.
You can monitor the execution in real-time through Pipedream’s interface, which shows the data flowing through each step. Once finished, you’ll find the generated analysis PDF in your /Pipedream/Analysis folder in Dropbox, ready for your hiring team to review.
Extending the Workflow
The resume analyzer we’ve built provides a solid foundation, but there are many ways you can extend it to better fit your hiring process. Here are some practical enhancements you might consider adding to make the workflow even more valuable for your organization.
You could add an email notification step that alerts hiring managers immediately when a new candidate analysis is ready. This notification could include key highlights from Claude’s analysis, such as the fit score and professional summary, along with a direct link to the full PDF report in Dropbox. This eliminates the need for hiring managers to constantly check the folder for new analyses.
Another useful extension is storing the structured JSON data in a database or spreadsheet. By adding a step that sends the parsed data to Airtable, Google Sheets, or your applicant tracking system, you can build a searchable database of all candidates. This makes it easy to filter candidates by skills, experience level, or fit score when you’re looking for specific qualifications.
You might also want to customize the analysis based on the position you’re hiring for. You could create different templates for different roles and use the filename or a designated folder structure to determine which template to use. For example, resumes in /Resumes/Engineering could use a template that emphasizes technical skills, while those in /Resumes/Sales could focus more on communication abilities and deal experience.
Conclusion
Building an automated resume analyzer with Pipedream, Claude, and DocuGenerate demonstrates how AI and workflow automation can transform time-consuming manual processes into efficient, consistent operations. The workflow we’ve created processes resumes in seconds, extracts meaningful insights that would take humans much longer to identify, and generates reports that make hiring decisions easier.
This approach is particularly valuable because it maintains consistency in candidate evaluation. Every resume is analyzed using the same criteria, reducing unconscious bias and ensuring that all candidates are assessed fairly. The structured format of the analysis reports also makes it easier to compare candidates side-by-side and identify the most promising applicants for your open positions.
The workflow pattern we’ve demonstrated here extends beyond resume analysis. The same approach of extracting text from documents, using AI to analyze and structure the content, and generating formatted reports can be applied to many other document processing scenarios. Whether you’re analyzing contracts, processing customer feedback, or extracting data from research papers, the core workflow remains similar with adjustments to the analysis prompt and output template.
Resources